SMOTE is a resampling method used in binary classification/regression. It oversamples the minority class by interpolating between 2 data points.

Two data points are considered. The first one is a key point and the other is taken using the K nearest neighbor. The interpolated point is calculated using the different and the gap as shown in the figure.
In the below example, a dataset with 100000 points are created. The feature is split as class 0 and 1 with a proportion of 99:1. Now the goal would be balance this dataset, so that the number of data points belonging to class 1 is close or equal the that of class 0.

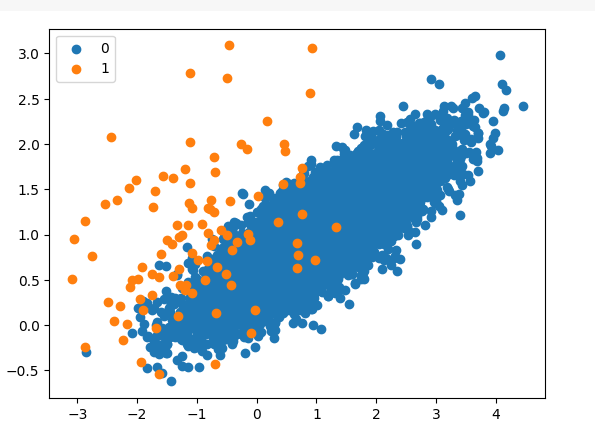
Further, the balancing of data is calculated as follows:


The output of a simple SMOTE is noisy and can be improved by:
- The number of synthetic points are huge and can be noisy. So an idea would be to undersample the majority samples and then apply the SMOTE to balance out the dataset.
- Oversample only using the key points that are often misclassified. The misclassified points can be used by classifiers like knn, svm etc. Example – Use the data points at the border as key points to interpolate and increase the dataset.
- Generate more synthetic data points only in low density area of the minority class.
